
其实在我们做csapp的lab时,最重要的是需要去阅读writeup,也就是实验基本的要求。本次实验分为两个部分,Part A要求我们模拟一个缓存命中计数器,PartB部分需要进行矩阵运算优化。
lab的具体内容可以在官网中下载,所有的lab代码在GitHub上。
1 Part A
需要在csim.c中写一个cache的simulator,使用LRU(least-recently used)替换原则,即替换最近最少使用的内存行。其以valgrind的memory trace作为输入,输出cache中的hit、miss和eviction总数。
1.1 需求分析
根据书本的知识,高速缓存块基本如下所示,
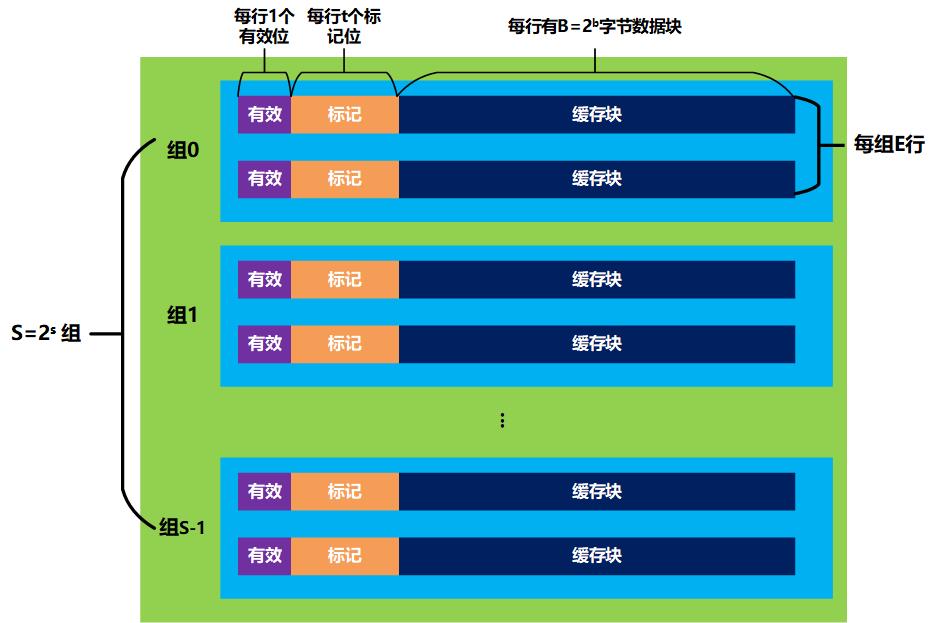
- 由于模拟器必须适应不同的s, E, b,所以数据结构必须动态申请(malloc系列);
- 测试数据中以“I”开头的是对指令缓存(i-cache)进行读写,我们直接忽略这些行;
- 此次实验假设内存全部对齐,即数据不会跨越block,所以测试数据里面的数据大小可以忽略;
- 由于没有实际的数据存储,所以我们不用实现高速缓存行(cache line)中的数据块部分;
- 实验要求使用LRU原则,即没有空模块(valid为0)时替换最早使用的那一个line,所以我们需要记录当前缓存行的时间参量,每次写入的时候更新该变量;
综上所述,我们给出以下结构体作为高速缓存行的基本结构,cache_line_t表示一个高速缓存行,cache_set_t表示一个高速缓存组,cache_t表示一个高速缓存。valid_bit表示有效位,只有一个bit,0表示无效,1表示有效,这里用int表示;tag_bits表示标记位;timestamp表示时间戳,当然,这里为了简便,直接用数值从0开始。
1 | typedef struct |
1.2 基本流程
设计代码的基本流程如下所示。
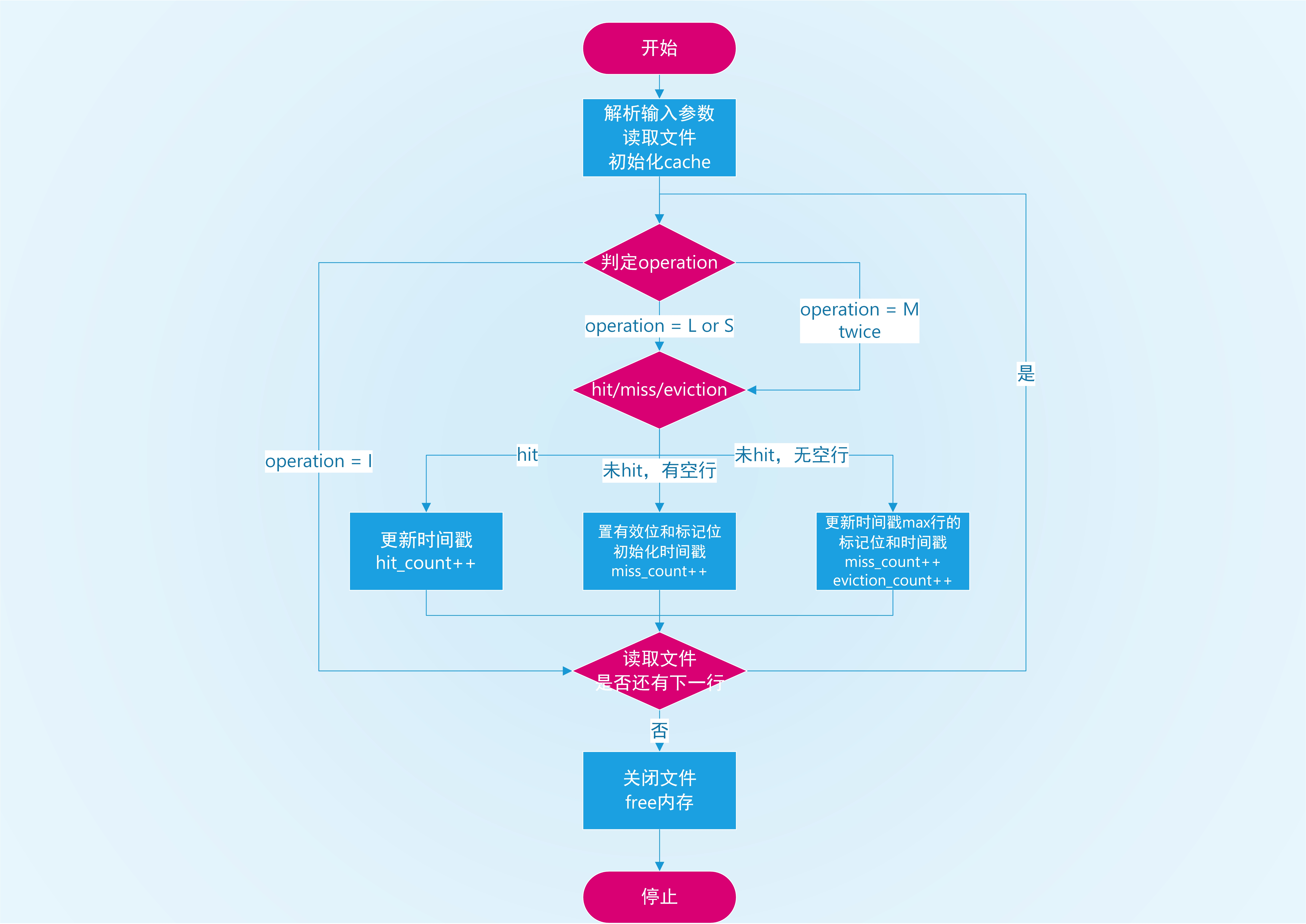
1.3 代码
基本的代码如下:
1 |
|
运行结果如下:
1 | ./test-csim |
2 Part B
Part B部分是优化矩阵转置,代码中给出了最简单的转置实现:
1 | for (i = 0; i < N; i++) { |
这个部分要求去完成trans.c文件中的transpose_submit函数,实现矩阵的转置。要求如下:
- 只准使用不超过12个int类型的局部变量,不允许使用long类型规避;
- 不允许使用递归;
- 如果使用辅助函数,则在辅助函数和顶级转置函数之间,一次最多不能有12个局部变量在堆栈上;
- 不允许修改数组A,但是可以对数组B做任何事情;
- 不允许在代码中定于任何数组或者使用malloc系列函数;
已经给定的cache参数是 s = 5,b = 5 ,E = 1。那么 cache 的大小就是 32 组,每组 1 行, 每行可存储 32 字节的数据。
2.1 32×32
在这个情况下,一行是32个int,也就是占据4个block,所以cache可以存8行,所以我们以8为单位进行分块,代码如下:
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) |
运行结果如下,可以看到距离满分的300还有距离。
1 | $ ./test-trans -N 32 -M 32 |
我们知道此题题设cache参数是(s = 5, E = 1, b = 5),对于32×32的矩阵数组,其字节大小是1024,而A和B的地址是连着的,也就是说A和B的相同位置的元素地址相差1024,我们假设A地址起始为(…. x000 0000 0000)b,那么B的起始地址就会是(…. x100 0000 0000)b,而cache参数的s和b都是5,根据地址组成,最后5位是块偏移,再5位是组索引,故而A 和 B 中相同位置的元素是映射在同一 cache line 上的,当A和B中的对角线位置时,譬如我们读取Aii处数据时,接下来会放到Bii处,因为二者映射的是同一行,使得第i行被替换成B的,但是随后又替换成A的,故而多造成了两次miss,所以我们修改代码如下,一次性读完一行,以减少不命中率,代码如下:
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) |
运行结果如下:
1 | $ ./test-trans -N 32 -M 32 |
2.2 64×64
2.2.1 8×8分块
对 64 x 64 的矩阵来说,每行有 64 个 int,则 cache 只能存矩阵的 4 行了,所以如果使用 8x8 的分块,一定会在写 B 的时候造成冲突,因为映射到了相同的块。看一下 8x8 的分块能达到多少 miss。
1 | if (M == 64 && N == 64) { |
而结果也达到了惊人的4600多次:
1 | $ ./test-trans -N 64 -M 64 |
2.2.2 4×4分块
代码如下:
1 | if (M == 64 && N == 64) { |
运行结果也达到了1699次,还是达不到要求。
1 | $ ./test-trans -N 64 -M 64 |
2.2.3 多次分块
这里我是参考网络的方法去做的,代码如下,分析过程直接看李秋豪。
1 | for (int i = 0; i < N; i += 8) |
执行结果如下,达到了满分要求。
1 | $ ./test-trans -N 64 -M 64 |
2.3 61×67
这题的要求比较宽松,所以我们直接用8×8分块,因为不是很对称,还需要对多余的部分进行一下处理,代码和得分如下:
1 | if (M == 61 && N == 67) { |
1 | $ ./test-trans -N 67 -M 61 |
总结
driver.py运行结果:
1 | $ ./driver.py |
cache-lab的难度还是相当大的,特别是Part B部分,虽然分块使得代码难以阅读和理解,但是学习和理解这项技术还是很有趣的。

